LoshSetter is finally here! If you want to play around with it, it's accessible by clicking this link. If you want to read the story of how making it took way longer than it should have, continue reading.
The Story of LoshSetter
For those of you who don't know, Losh is a writing system created by myself and a friend of mine back in the winter of 2021/2022. It's a featural alphabet inspired by Hangeul and Devanagari, and can be used to write American English. For more info on Losh, consult this PDF.
While Losh was already a fun project on its own, I wanted to try taking it a step further and seeing if I could make a program to typeset documents with it. And so began my year-long journey to create LoshSetter, inspired by Donald Knuth's famous LaTeX software.
The First Attempt
My first attempt at creating a typesetting program began almost exactly one year ago, in between studying for different final exams. Though these efforts lasted about a day, I took important lessons away from them—namely that the renderer would have to treat consonants and vowels differently, and that organizing the text into words and letters might be just as hard as the rendering itself.
Though I made some progress in getting letters to display on the screen, the combined forces of statics, differential equations, and electrodynamics soon forced me away from Losh and back into the library. I would return to the project…
After a long and restful winter break.
The Second Attempt
My second attempt at creating LoshSetter picked up about a month after I'd stopped the first. I made very fast progress; within a day, I had gone from rendering the letters B and P to rendering all of the consonants with spaces and automatic line breaks. The next day saw me rendering vowels and fixing the kerning of the font. At this pace, it seemed like LoshSetter might be done in a week! A month at most, maybe.
The next few days saw the addition of feature after feature. First I added support for numbers. Then came punctuation. Unicode support followed soon after. By the end of the week, I'd begun adding LaTeX-inspired commands to change the font on the fly.
![There [should] be some regular text, and **these 3 words** should be bold. No one should be able to understand this. \\ `Also supports English Rendering! 日本語もできるぞ! *Make me Italic!*`](/uploads/2024/12/1734470498876-2a.png)
With this rapid development of new features, however, came a couple of issues. First, bloat. The codebase was starting to get a bit disheveled, and every feature I added cost me some technical debt in refactoring the code later.
Second, vectorization. The first prototypes of LoshSetter worked with the Canvas API, which rendered everything to a raster canvas. There's a reason that we usually save text as a PDF or other document instead of an image, and talking to others about the project made me realize that I wanted to take advantage of the smooth zooming and small file sizes of vectorized text.
And third, parsing. It was simple enough to make a system that rendered only Losh text. But adding support for punctuation and Unicode text made things much more complex, and the addition of commands to change styling and layout only worsened this problem. I didn't realize it at the time, but this would soon become the most difficult part of the entire project.
Vectorization was easy enough; the renderer was already rendering things letter by letter, so all it took was replacing the polylines with SVG paths and then arranging said paths to match how they were originally rendered. I also took the next couple weeks to try and deal with the bloat by splitting out more helper functions from the rendering process.
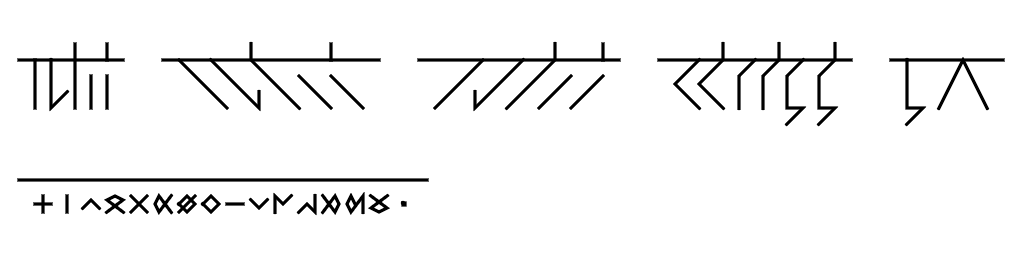
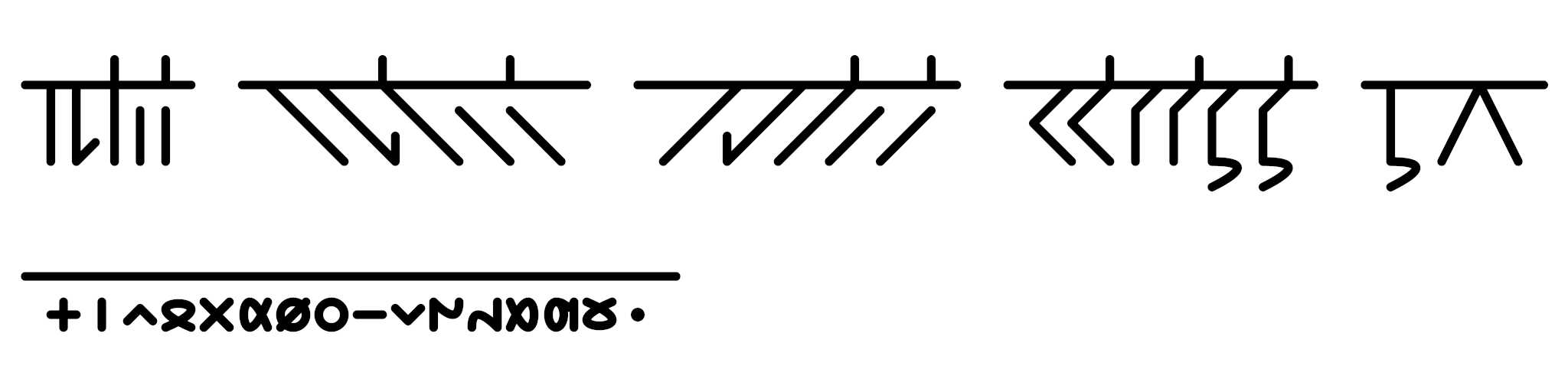
But the issue of parsing through text with four different types of chunks was bigger than I'd made it out to be. Two weeks came and went and I'd barely made any progress on the front. The possibility that I might need to completely rework not only the parsing engine but also the markup language was creeping up on me, and with another round of exams coming around, I was once again forced to shelve the project.
The Third Attempt (The Successful One)
It took a while for me to come back to LoshSetter. In the spring, I set it onto the back burner to work on rewriting The Squishy Lab in Javascript. It wasn't until August that I came back and decided that I'd finish LoshSetter once and for all.
The main issue to tackle was the syntax and parsing; if I could fix that, then everything else would fall into place quickly.
Looking back, it's pretty easy to see why parsing was such a problem. The way that LoshSetter was originally configured was that one would have to first declare the document's page setup and rendering settings as properties of a LoshDocument instance. Then the contents of the document were written in plain text interspersed with commands. Some commands had similar syntax to LaTeX, such as \lineheight{15}, while others were taken straight from BBCode, like [fontcolor=red]. Juggling multiple types of commands, Losh text, Unicode text, numbers, punctuation and whitespace all at once was a recipe for disaster. There had to be a better way!
After some thought, I realized that the best way to organize documents would be less like the linear structure of RTF files, and more like the ordered tree structure of XML. Instead of feeding commands to the renderer in real time, it'd be much easier to describe the structure of the document beforehand and properly lay it out before starting to render any text.
And so I drafted plans for a new LoshSetter, one that would use HTML-inspired syntax and have a clear, defined rendering process:
- Extract Document Data. The new syntax would contain the document's page data and metadata in a
<head>tag. Including this in the document itself would allow for LoshSetter to only have to take in a single text stream as input, rather than having to define parameters in code. - Traverse the Document. This is where making the syntax into XML came in; defining the documents in this way allowed for a simple XML parser to do the work of making sense of the content's structure, which made it easier to keep track of everything.
- Tokenize the Text. With styles and layout defined by the XML tags, the next step was to parse the text within them. Differentiating Losh phonetics from plain Unicode text was no longer an issue, as any Unicode text was contained within
<unicode>tags. From here, helper functions could be used to split words, numerals, punctuation, and whitespace. - Calculate the Layout. With every element separated and defined, the program could now calculate their sizes and use the data to lay the document out word by word. This would then produce a map of what elements to render and where to render them, which could then be sent to any export pipeline.
- Render the Document. While the previous version of LoshSetter had integrated everything into one process, this new pipeline was agnostic to the rendering engine. Now the program could take the render data from the previous step and use it to generate a raster or vector output.
With this process planned out, all that was left to implement it—a process that only took a couple of weeks, given that I'd essentially finished the text renderer with my second attempt. The structure of a Losh Document can be seen below:
<document>
├── <head>
│ ├── <page/>
│ │ ├── width
│ │ └── height
│ ├── <margins/>
│ │ ├── top
│ │ ├── left
│ │ ├── right
│ │ └── bottom
│ ├── <title>
│ ├── <author>
│ ├── <subject>
│ └── <keywords>
└── <body>
├── block elements (<p>, <h1>, etc.)
│ ├── inline elements (<b>, <span>, etc.)
│ │ ├── plain text
│ │ └── unicode text
│ ├── plain text
│ └── unicode text
├── inline elements
│ ├── plain text
│ └── unicode text
│
├── plain text
│ ├── losh words
│ ├── numerals
│ ├── punctuation
│ └── whitespace
└── unicode text
├── non-whitespace
└── whitespaceAnd with the document renderer finished, all that was left was to create a nice interface for using it!
The Interface
Though I'd finished the renderer in late August, I felt that it needed a graphical interface before I could put it out for the world to see.
Taking inspiration from the computers of the early 2000's, I whipped up a quick layout in HTML and CSS, so that it could run in the browser. Though I'd worked plenty with Svelte by this point, I figured that it wouldn't be too difficult to manage this in vanilla Javascript. This would prove to be a mistake.
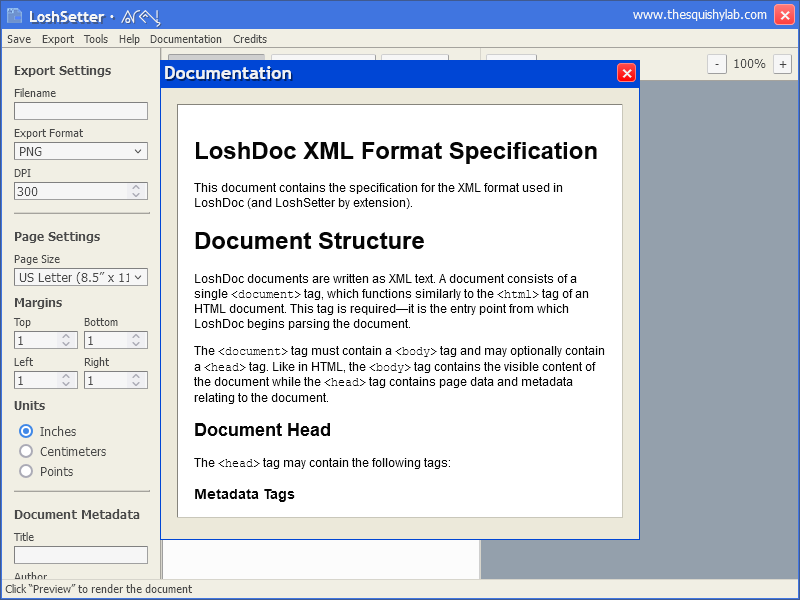
Long story short, I faced two main challenges in creating the interface for LoshSetter. The first was getting the renderer to run in the browser, which was actually quite easy thanks to the Canvas API and PDFKit both being able to run in the browser.
The second challenge was getting the interface to be somewhat user-friendly, which took a lot of work in both state management and interactivity. What I learned (or re-learned, if I'm being honest) from this part is that there's a reason that we have libraries like React and Svelte, and that I should probably be using them more.
But with the interface and documentation finished, I'm finally ready to put LoshSetter up onto The Squishy Lab! I hope you all enjoy playing around with it; it's hard for me to not be proud after a whole year of putting this thing together.
I'll try to have more projects up soon; these are really fun for me to make and I'm happy to share them with the world. Until then, stay tuned!
Log in to comment on posts.
Nothing here yet. Be the first to comment!